
Strands vs. Claude Agent SDK: Two Very Different Bets on What “Agent” Means
A technical deep-dive into the architectural trade-offs between AWS Strands Agents and the Anthropic Claude Agent SDK, including the real story on running non-Claude models through the Agent SDK.


Most comparisons lay these two side by side in neat feature tables. That’s useful but insufficient, because the frameworks don’t just differ in features. They differ in their assumptions about your problem. Pick the wrong one, and you’ll spend weeks building plumbing that the other gives you for free, or discover your architecture can’t flex in the direction your product needs.
This article breaks down the real architectural differences, compares them feature by feature (with attention to TypeScript support), and digs into the question that keeps coming up: can you actually run non-Claude models through the Claude Agent SDK?
Orchestrator vs. Runtime
There is a subtle but significant difference in approach between Strands and the Claude Agent SDK. The latter gives your agent a brain and a dispatch loop. You build the hands, providing the LLM with a prompt, tool definitions (name, description, input schema), and a system prompt. The model decides which tools to call and in what order. The framework manages the loop: call model → model picks a tool → framework invokes your callback → feeds result back → repeat. The keyword is your callback. The tool definition says get_weather takes a location string, but you’re responsible for wiring that to an actual HTTP call, handling errors, and returning the result.
On the other hand Claude Agent SDK gives your agent a brain, hands, a workbench, and a filing cabinet. Your job is to decide what is not allowed to be touched. The SDK ships with pre-built, executable tools: Read, Write, Edit, MultiEdit, Bash, Glob, Grep, WebSearch, WebFetch, AskUserQuestion, Agent (subagent spawning), and NotebookEdit. When Claude decides to read a file, the SDK reads that file from the filesystem. When it decides to run grep -r "TODO" ./src, a real shell executes that command and feeds stdout back. This is the same infrastructure that powers Claude Code, repackaged as a programmable library.
The practical consequence shows up during debugging. A Strands agent calling a proprietary API gives you normal debugging: step through the callback, inspect the raw HTTP response, and add retries. A misbehaving Claude Agent SDK agent means figuring out what Claude thought the filesystem looked like versus what it actually looked like. Different kind of problem.
With Strands, the agent starts with zero capabilities. The agent does not have “agency”: You add tools one by one. With the Claude Agent SDK, the agent starts with a shell, a filesystem, and web access. Your job is to restrict what it can touch. Miss a permission? The agent might execute something you didn’t expect. The allowed_tools list and permission modes help, but the mental model is fundamentally different: you’re not building a whitelist, you’re maintaining a blacklist. And blacklists have gaps.
This means Claude Agent SDK workloads should run in sandboxed containers, gVisor at minimum, not Docker alone. The performance overhead is real (roughly 15-20% on I/O-heavy operations), but the alternative is trusting that you’ve correctly anticipated every shell command a sufficiently creative LLM might construct. Firecracker would provide even stronger isolation, a true microVM, and a minimal attack surface, but the cold-start latency (~125ms, which compounds in agentic loops with dozens of tool calls) makes it impractical for interactive workloads. Batch processing is a different story.
Feature matrices date fast, and half these checkboxes will be different in six months. Treat this as a snapshot.
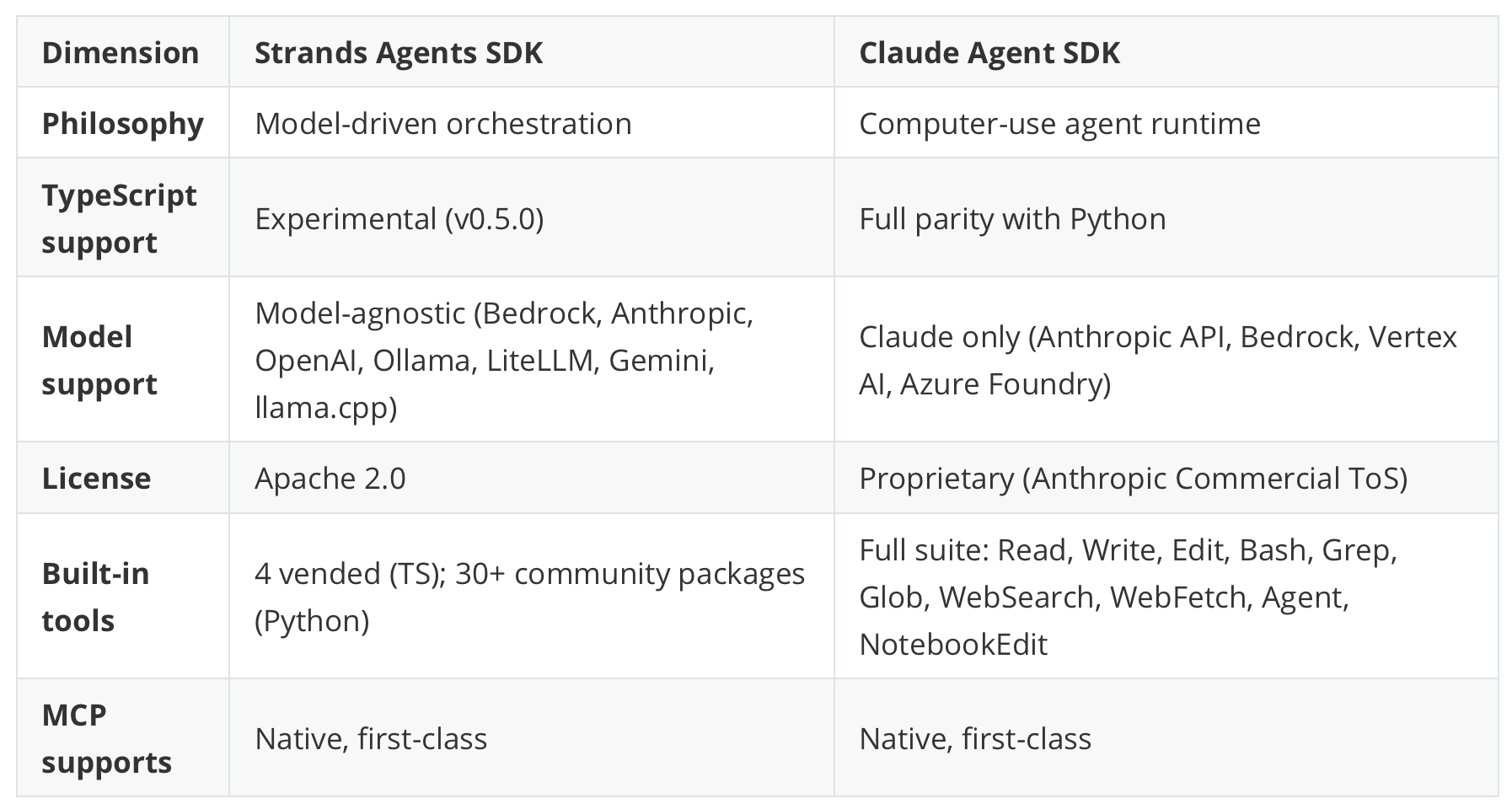
A relevant point on MCP: both claim first-class support, both deliver it, but they feel different in practice: Strands treats MCP tools the same as any other tool definition, registers the server, and tools appear in the list. The Claude Agent SDK integrates MCP more deeply because its tools are already executable; MCP servers plug into the same execution pipeline as built-in tools. For simple tool schemas, this distinction doesn’t matter. For tools with complex input validation, the Claude Agent SDK’s execution model handles it more gracefully.
Strands offers Graph, Swarm, Workflow, and Agent-as-Tool. Different agents can use different models; this matters for cost optimization: cheap models for classification and routing, expensive ones for reasoning. The Claude Agent SDK provides subagents with isolated context windows, all of which run Claude. Simpler to reason about, inflexible on model choice.
On the observability side, Strands has OpenTelemetry support only for Python; the TS SDK is missing it, which is frustrating if you’re a TypeScript shop. The Claude Agent SDK includes built-in cost tracking and lifecycle hooks (PreToolUse, PostToolUse, SubagentStart/Stop) to wire in custom telemetry. More assembly required, but more flexible.
The Claude Agent SDK ships a max_budget_usd parameter that caps spend per session. Strands has no equivalent; you’ll need to build a token-counting middleware yourself. Not hard, but the kind of thing a framework should handle.
Strands integrates with Lambda, Fargate, EKS, and recently AgentCore. The Claude Agent SDK assumes sandboxed containers. Running both on EKS is feasible, but Claude Agent SDK pods need the gVisor runtime class, which means separate node pool configuration.
A special focus should be placed on TypeScript-first support; the comparison is lopsided. Strands TS SDK v0.5.0 is marked experimental. The core agent loop works and is usable, but the official docs list these as Python-only: Anthropic/Ollama/LiteLLM model providers, summarizing conversation manager, multi-agent patterns, session persistence, OpenTelemetry, the Evals SDK, and the community tools package. The GitHub README hints that some of these (structured output, Graph/Swarm) have landed in TS recently, but the docs haven’t caught up. There are known edge cases. Graph mode with parallel nodes can deadlock when concurrent nodes write to the same session store. On the other side, Claude Agent SDK TS (@anthropic-ai/claude-agent-sdk, v0.2.71) has full feature parity with the Python version. Hooks, custom MCP tools, subagents, streaming, sessions, the complete tool suite, all there. Porting an agent from Python to TS requires only syntax changes. That’s rare in this ecosystem.
For TypeScript teams that need production-ready agent capabilities now, the gap is hard to ignore.
Running Non-Claude Models Through the Claude Agent SDK
It is an often-asked question, with a mixed response from the community: “Can I use Claude Agent SDK with non-Claude models?” Short answer: You can; it mostly works. Don’t do it in production. The Claude Agent SDK officially supports only Claude models through four backends: the Anthropic API, Amazon Bedrock, Google Vertex AI, and Microsoft Azure AI Foundry. There is no native abstraction for model providers. The SDK spawns a Claude Code CLI subprocess that expects the Anthropic Messages API format.
There are different approaches to running non-Claude models, but they are all workarounds: Ollama’s Anthropic API compatibility layer, overriding ANTHROPIC_BASE_URL to point to Ollama, setting a dummy auth token, and the agent loop runs. Models tested include qwen3.5, glm-5:cloud, and kimi-k2.5:cloud. Ollama recommends a 64k context minimum, which significantly limits model choices. Another solution is to use the LiteLLM proxy, which translates the Anthropic Messages API to any backend provider (OpenAI, Azure, Gemini, Bedrock, Ollama, 100+ others). More flexible than Ollama’s built-in compatibility. Point ANTHROPIC_BASE_URL at the proxy, and the same agent code works with any model. Another way could be using Claude Code Router (a community project), which enables dynamic model switching within sessions. Supports OpenRouter, DeepSeek, Ollama, and Gemini.
Nice ideas, but they actually break in production
Tool-calling reliability degrades noticeably. In benchmarks comparing Claude Sonnet 4 against Qwen3.5 via Ollama compatibility on identical task sets (file operations, grep searches, multi-step bash workflows), Claude completes ~95% of tasks correctly, while Qwen completes around 60%, with most failures in multi-step bash tasks where it constructs syntactically valid but semantically incorrect commands. The Claude Agent SDK faithfully executes those incorrect commands. Powerful runtime plus mediocre reasoning equals a larger blast radius, arguably worse than the same model running in a simpler framework.
Extended thinking is very limited outside of Claude. If agent workflows depend on it (complex code review, deep research, multi-step planning), there’s no workaround. The agent often runs without extended thinking capabilities, and it makes worse decisions at the planning stage.
Subagent orchestration assumes Claude-level instruction following. Permission hooks behave unpredictably with weaker models; the model occasionally tries to use disallowed tools, the SDK blocks it correctly, but the recovery behavior (trying an alternative approach) isn’t as graceful as with Claude.
The bottom line is that using other models than Claude is technically feasible via proxy layers, but architecturally unsound for production. The SDK is a Claude-specific runtime being adapted through API translation, not a model-agnostic framework.
When to Use Which
We found that Strands is the right choice for domain-specific agents. Agents calling proprietary APIs (legal corpora, scoring engines, internal services), multi-model architectures where different agents use different LLMs, edge deployment with local models, AWS-native event-driven patterns (Lambda, EventBridge, S3 triggers), and situations where Apache 2.0 licensing or vendor independence are requirements. The cost flexibility alone, swapping an expensive model for a cheap one on a per-agent basis, justifies the choice for most enterprise use cases. On the other hand, the Claude Agent SDK is the right choice when agents need to interact with a computing environment. Code review, codebase analysis, research tasks involving document reading and web search, and any workflow where the agent needs to read, write, edit, and execute. The built-in tools eliminate enormous amounts of boilerplate. Replicating the Edit tool’s diff-based file editing with conflict detection in Strands is a multi-day effort; it’s not trivial.
Sometimes, having both in the same system makes sense: when a pipeline has domain-specific ingestion and classification (Strands, multiple models, custom tools) feeding into compute-heavy analysis and report generation (Claude Agent SDK, file I/O, shell access, web search). The agent layers communicate via MCP. It works, but the operational overhead of two runtimes is real. Don’t add this complexity unless you genuinely need both capability sets. Note that AWS demonstrated a similar pattern in their financial analysis reference architecture: LangGraph for workflow orchestration, Strands for reasoning within workflow nodes.
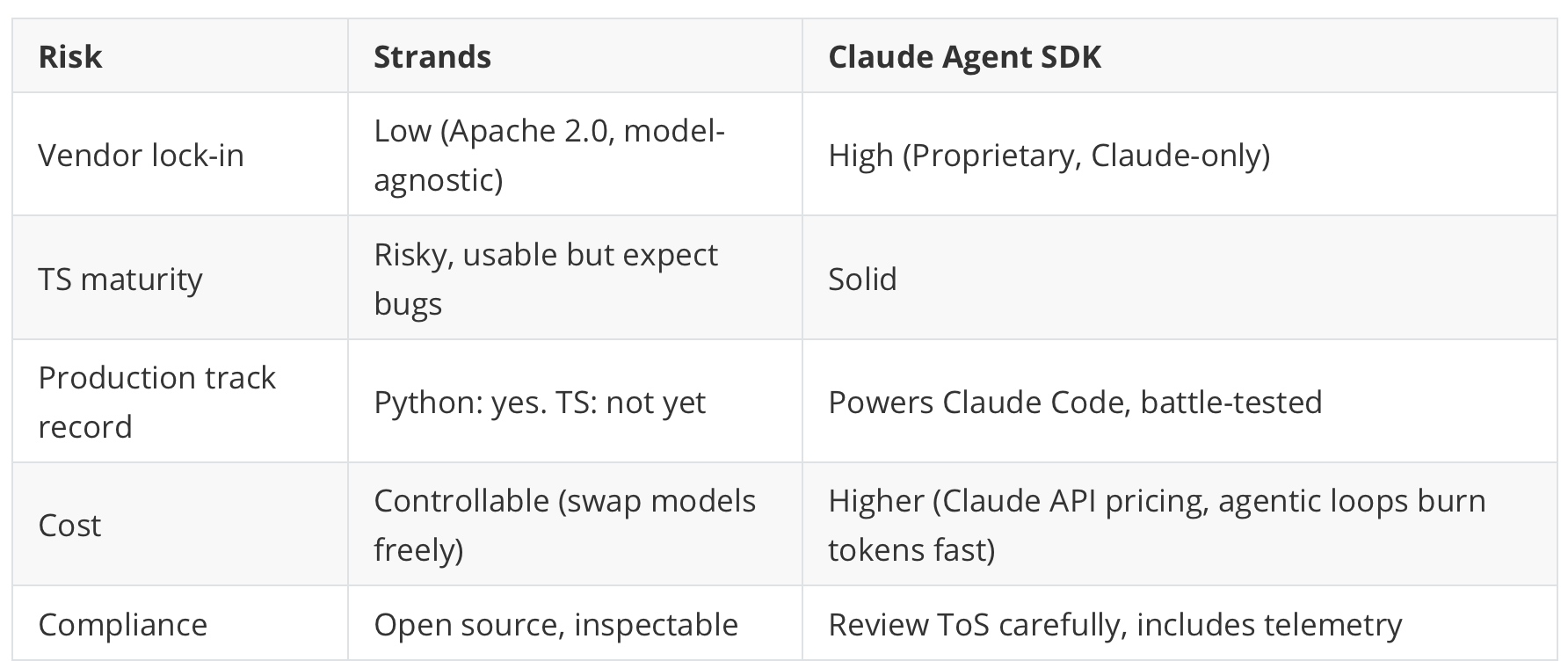
One thing the table doesn’t capture: the Claude Agent SDK’s proprietary license means you can’t fork it if Anthropic changes terms or pricing. With Strands, worst case, you have the source code. In enterprise procurement, this distinction matters more than most engineers think.
Where to go from here
Both frameworks have native MCP support, which means tools built for one are increasingly portable to the other. Neither has A2A (agent-to-agent protocol) yet, CrewAI does, for what it’s worth.
The practical takeaway: write all new tools as MCP servers regardless of which framework consumes them. If Strands need to be swapped for something else in a year, the tools survive. If the Claude Agent SDK adds model-agnostic support (unlikely but not impossible), the tools still survive.
The framework is a replaceable component. The tools and the domain logic aren’t. Invest accordingly.
Subscribe to TechOnTheStack for weekly deep-dives on cloud architecture, AI infrastructure, and hands-on engineering decisions. No fluff, just what works and what doesn’t.